张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 模型 - 第9页
TensorFlow Recommenders 迎来更新 — 可扩展检索和特征交互建模_tensorflowforum的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 560次

9月,我们开源了TensorFlowRecommenders,这个库能够帮助您轻松构建最先进的推荐系统模9文:RuoxiWang、PhilSun、RakeshShivanna和MaciejKula,Google 9月,我们开源了 TensorFlowRecommenders,这个库能够帮助您轻松构建最先进的推荐系统模型。现在,我们高兴地宣布TensorFlowRecommenders(TFRS)的新版本 v0.3.0。TensorFlowRecommendershttps://mp.weixin.qq
第三届北京智源大会开幕,全球最大智能模型“悟道2.0”重磅发布_AI科技大本营
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 650次

6月1日,由北京智源人工智能研究院(以下简称智源研究院)主办的2021北京智源大会在北京中关村国家自主创新示范区会议中心成功开幕。北京智源大会是智源研究院主办的年度国际性人工智能高端学术交流活动,定位于“AI内行顶级盛会”,2019年举办了首届大会,今年为第三届,6月1日至3日线上线下同步召开,超过3万多名人工智能领域专业人士注册参会。 大会开幕式上,北京市副市长靳伟、科技部战略规划司司长许倞出席并致辞。靳伟副市长在致辞中指出,近年来,北京市大力推动人工智能的加速发展&#
深度学习100例-卷积神经网络(VGG-19)识别灵笼中的人物 | 第7天_K同学啊
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 639次
文章目录一、前期工作1.设置GPU2.导入数据3.查看数据二、数据预处理1.加载数据2.可视化数据3.再次检查数据4.配置数据集5.归一化三、构建VGG-19网络1.官方模型(已打包好)2.自建模型3.网络结构图四、编译五、训练模型六、模型评估七、保存and加载模型八、预测一、前期工作本文将实现灵笼中人物角色的识别。较上一篇文章,这次我采用了VGG-19结构,并增加了预测与保存and加载模型两个部分。
深度学习100例-卷积神经网络(VGG-16)识别海贼王草帽一伙 | 第6天_K同学啊_vgg神经网络
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 656次
文章目录一、前期工作1.设置GPU2.导入数据3.查看数据二、数据预处理1.加载数据2.可视化数据3.再次检查数据4.配置数据集5.归一化三、构建VGG-16网络1.官方模型(已打包好)2.自建模型3.网络结构图四、编译五、训练模型六、模型评估一、前期工作本文将实现海贼王中人物角色的识别。我的环境:语言环境:Python3.6.5编译器:jupyternotebook深度学习环境
案例分享 | CEVA 使用 TensorFlow Lite 在边缘设备部署语音识别引擎及前端_tensorflowforum的博客
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 637次

客座博文/IdoGus,来自CEVA CEVA 是无线连接和智能传感技术的领先授权商。我们的产品可帮助原始设备制造商(OEM)为移动设备、消费者、汽车、机器人、工业和物联网等多种终端市场,设计节能、智能和联网的设备。CEVAhttps://www.ceva-dsp.com/在本文中,我们将说明如何使用适用于微控制器的TensorFlowLite (TensorFlowLiteforMicrocontrollers,TFLM),在基于CEVA-BXDSP内核的裸机开发板上部署名为WhisPro的语音识别引擎及前端。WhisPro可在设备端有
Transformer 原理讲解以及在 CV 领域的应用_迈微AI研习社 · 号主
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 705次
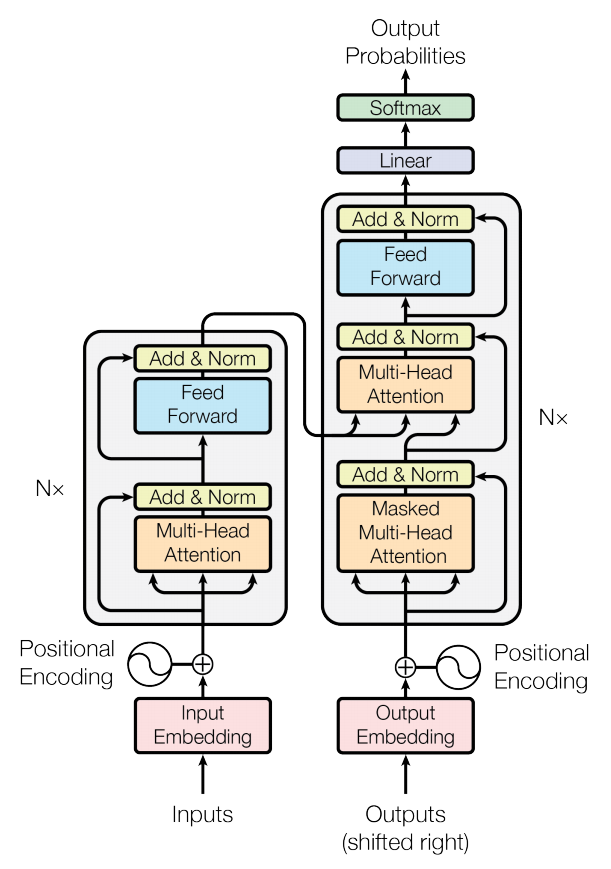
本篇文章选自GitHub《计算机视觉实战演练:算法与应用》第17章节,全文请参考 https://github.com/Charmve/computer-vision-in-action 本书主要以实战为主,基础理论篇主要讲解神经网络模型,结合常见的手写字识别、图像分类、车道线检测、人脸识别项目、实力分割等实战演练.更主要的特点在于,系统的整理了前沿的计算机视觉模型,例如注意力机制、跨界模型transformer、dert等新型深度学习模型。适合掌握基本算法知识,一定编程能力的朋友入手。GitHub已发布几章篇目,欢迎大
2020 泰迪杯 C 题_zhuo木鸟的博客
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 657次

然后以留言详情为输入数据,以一级标签为输出标签,于是问题转换为一个文本分类的问题。因此,我们需要将非结构型文本数据转换为结构型文本数据(表格);将文本标签(一级标签)转换为自然数,以表示类别,如下所示:

2020泰迪杯C题,含数据代码思路第一问数据预处理二元语法词袋模型分类模型机器学习方法多层感知器模型结果第二问数据预处理分词停用词过滤词袋模型PCA降维热度挖掘话题——聚类热点描述第三问答复相关性词向量相似度计算答复完整性(代码没有实现)代码和数据返回目录思路具体思路请见:https://blog.csdn.net/weixin_42141390/article/detail
开源图像识别、imageai图像识别、对象识别、识别人、车、猫、狗等80种 简易版_Baldprogrammer的博客
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 604次
imageai官网地址:传送门详细版地址:https://blog.csdn.net/Baldprogrammer/article/details/116358180项目地址:传送门1、安装环境(最终版)安装python-3.6.8-amd64一键安装,勾选添加到path中安装imageAI--官网地址:https://imageai-cn.readthedocs.io/zh_CN/latest/I
基于无监督深度学习的单目视觉的深度和自身运动轨迹估计的深度神经模型_soaring_casia的专栏
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 601次

本文是对文章《UnsupervisedLearningofDepthandEgo-MotionfromVideo》的解读。Figure1.深度图和Ground-Truth[1]Figure2.AbsoluteTrajectoryError(ATE)onKITTIdataset[1]1.概述1.1为什么要讲这篇文章?在无人驾驶、3D重建和AR三个领域中,对于周围环境物体的深度(Depth)和对自身位置的估计(StateEstimation)一直是一个非常棘手而复杂的问题。过去常用的方法,传统的SLAM,通常用非常繁琐的数学公式
tensorflow+k-means聚类 简单实现猫狗图像分类_叶庭云 成为自己的光
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 633次
文章目录一、前言二、k-means聚类三、图像分类一、前言本文使用的是kaggle猫狗大战的数据集:https://www.kaggle.com/c/dogs-vs-cats/data训练集中有25000张图像,测试集中有12500张图像。作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可。通过使用更大、更复杂的模型,可以获得更高的准确率,预训练模型是一个很好
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1