爬虫问题分析
回顾
之前写了一个爬取小说网站的多线程爬虫,操作流程如下:
先爬取小说介绍页,获取所有章节信息(章节名称,章节对应阅读链接),然后使用多线程的方式(pool = Pool(50)),通过章节的阅读链接爬取章节正文并保存为本地markdown文件。(代码见文末 run01.python)
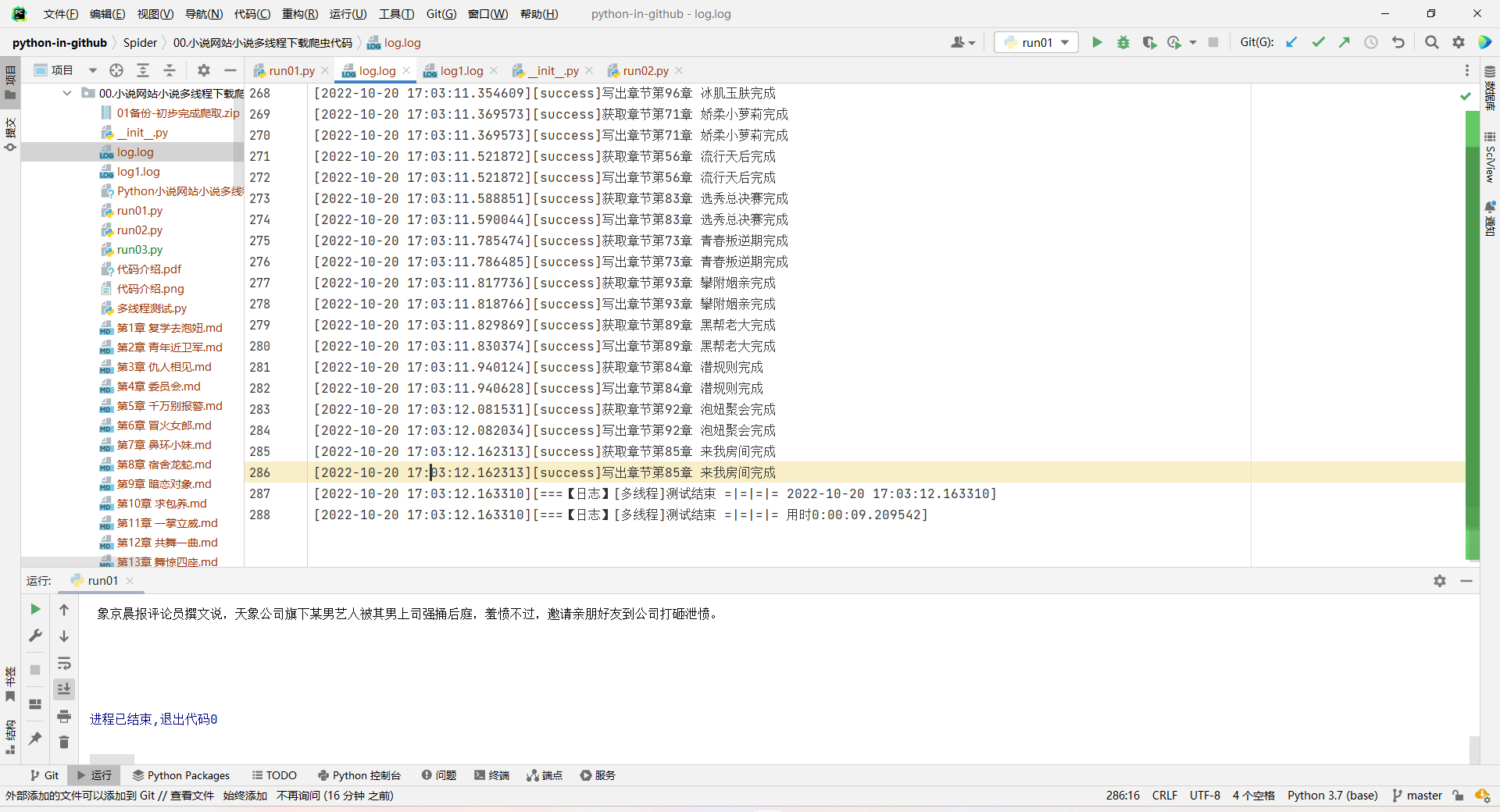

爬取100章,用了10秒
限制爬取101章,从运行程序到结束程序,用时9秒
Redis+MongoDB,无多线程
最近学了Redis和MongoDB,要求爬取后将章节链接放在redis,然后通过读取redis的章节链接来进行爬取。(代码见文末run02.python)
…不用测试了,一章一章读真的太慢了!

爬取101章用时两分钟!
Redis+MongoDB+多线程


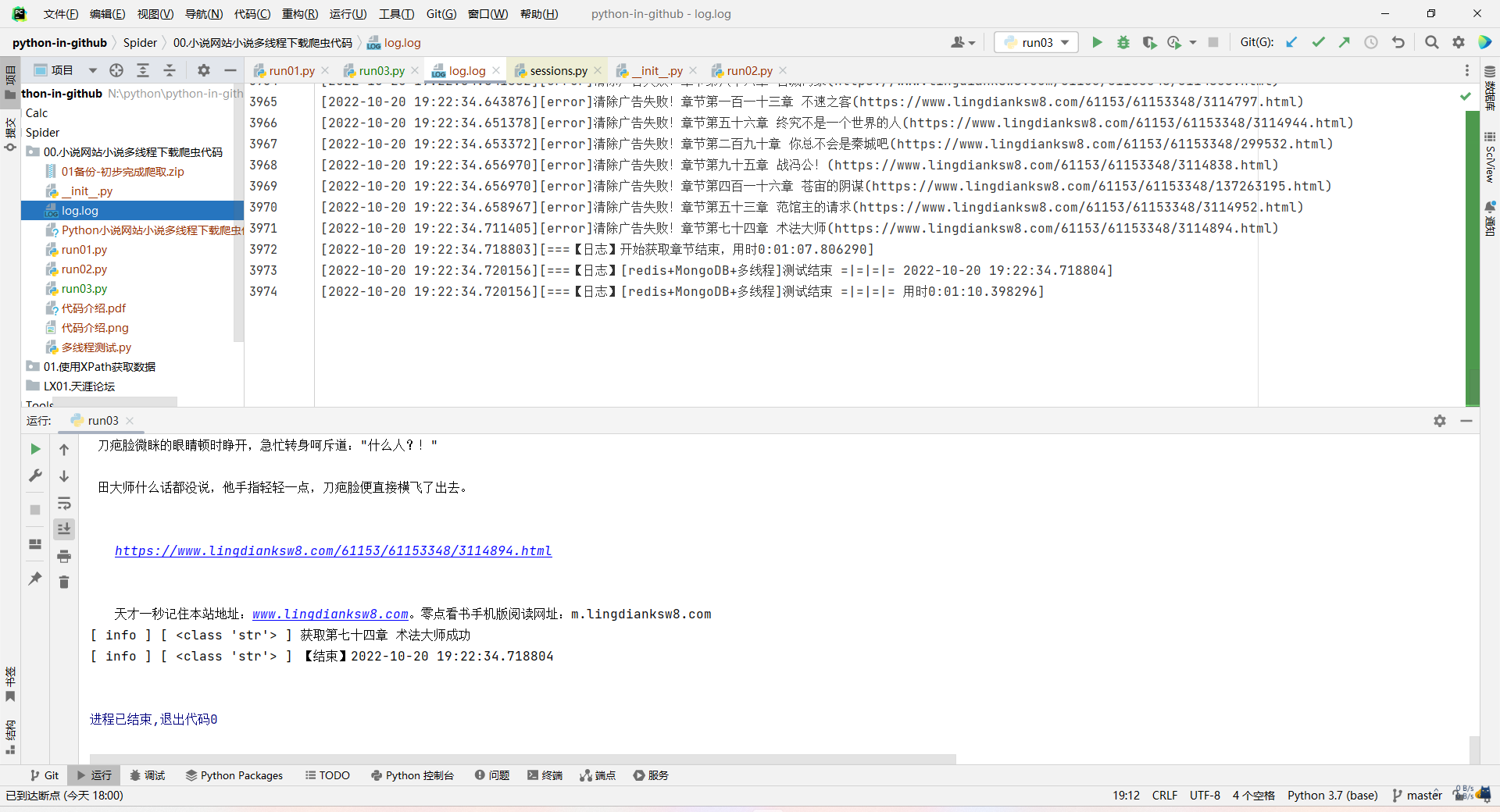
爬取101章,只需8秒!
爬取4012章,用时1分10秒!
问题与解析
懒得打字,我就录成视频发在小破站上面了。(小破站搜:萌狼蓝天)
[爬狼]Python爬虫经验分享第1节:代码文件简单介绍
[爬狼]Python爬虫经验分享第2节:编码问题的处理
[爬狼]Python爬虫经验分享第3节:多线程爬小说的顺序问题解决方案分享
[爬狼]Python爬虫经验分享第4节:爬取过于频繁被拦截的解决方案
其他的去我小破站主页翻
代码20221020
run01.py
# -*- coding: UTF-8 -*-# 开发人员:萌狼蓝天# 博客:Https://mllt.cc# 笔记:Https://cnblogs.com/mllt# 哔哩哔哩/