本文目录 文末有送书福利~
一、AI编译器的定义二、AI工程师的职业未来发展三、推荐书籍《AI编译器开发指南》四、送书福利~
如今随着科技不断的发展,技术的不断革新,开发者们不断面临着各种新的场景与挑战,例如大数据、人工智能、深度学习、大规模集群计算、更复杂的网络环境、多核处理器引起对于高并发的需求,云计算、云处理等等……在这个环境下,AI编译器横空出世了。
前段时间,昇思-MindSpore在B站上举办了一次AI编译器的论坛,会议邀请了赵捷、蒋力、田野以及淡孝强几位老师进行了分享。这里我结合自己的了解和所学知识及网上资料给大家简单科普介绍一下AI编译器方面的一些知识。
一、AI编译器的定义
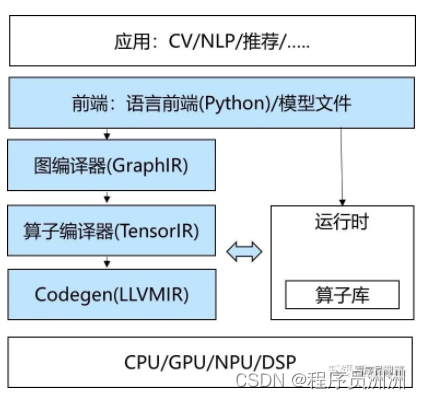
AI编译器有几个明显的特征:
1、Python为主的动态解释器语言前端
与传统编译器不同,AI编译器通常不需要Lexer/Parser,而是基于前端语言(主要是Python)的AST将模型解析并构造为计算图IR,侧重于保留shape、layout等Tensor计算特征信息,当然部分编译器还能保留控制流的信息。
这里的难点在于,Python是一种灵活度极高的解释执行的语言,AI编译器需要把它转到静态的IR上。
2、多层IR设计:
为什么需要多层IR设计,主要是为了同时满足易用性与高性能这两类需求。为了让开发者使用方便,框架前端(图层)会尽量对Tensor计算进行抽象封装,开发者只要关注逻辑意义上的模型和算子;而在后端算子性能优化时,又可以打破算子的边界,从更细粒度的循环调度等维度,结合不同的硬件特点完成优化。因此,多层IR设计无疑是较好的选择。
3、面向神经网络的特定优化
数据类型-Tensor:AI领域,计算被抽象成张量的计算,这就意味着AI编译器中主要处理的数据类型也是张量,这个是非常重要的前提。
自动微分:BP是深度学习/神经网络最有代表的部分,目前相对已经比较成熟,基于计算图的自动微分、基于Tape和运算符重载的自动微分方案、基于source2source的自动微分都是现在主流的方案。
自动并行:随着深度学习的模型规模越来越大,模型的并行优化也成为编译优化的一部分,包括:数据并行、算子级模型并行、Pipeline模型并行、优化器模型并行和重计算等。
4、DSA芯片架构的支持
SIMT、SIMD、Dataflow:AI的训练和推理对性能和时延都非常敏感,所以大量使用加速器进行计算,所以AI编译器其实是以加速器为中心的编译器,这个也是区别于通用编译器的一个特征。
二、AI工程师的职业未来发展
上某网一看,就能发现年薪40W的工作基本上是起步价格。高薪难求合格的AI工程师。
三、推荐书籍《AI编译器开发指南》
所以说,AI编译器开发未来有很好的发展趋势并非空口而谈,相信很多行动力很强的小伙伴都已经跃跃欲试了。
磨刀不误砍柴工,好的教学往往能够让新手小白事半功倍,这里,我给大家推荐一本书:《 AI编译器开发指南》,从实战编程的角度出发,全方位阐述AI编译器技术,帮助初学者建立AI编译器开发领域知识图谱。
本书是国内首本AI编译器图书!能够告诉读者如何直击行业痛点。可以说是新手小白入门必备的一本书!
本书的一些优势与看点:
1、综合了各种现有的AI编译器设计理论和实践成果,对AI编译器领域关键技术进行了系统的梳理、全方位、全维度的展现了相关知识。
2、从开发实战的角度出发,将抽象的编译器概念进行形象化的表述,并且以开源项目中的源代码分析,提高开发者的实际解决问题的能力!
3、附有大量讲解视频+核心资料助你事半功倍掌握新兴技术!
四、送书福利~
参与条件:
评论区评论你与AI编译器之间的故事,随机抽取3位小伙伴获赠**《AI编译器开发指南》**各一本!
图书由机械工业出版社赞助~活动截止本周五晚八点~(2月3号)
也可直接去京东官网直接购买!~