文章目录
本文导读1. 关联规则分析2. 回归分析3. 分类分析4. 聚类分析5. 集成学习6. 自然语言处理7. 图像处理8. 深度学习9. 书籍推荐(包邮送书6本)
本文导读
从零带你了解人工智能时代需要掌握的8大类算法,包括基础理论、关联规则分析、回归分析、分类分析、聚类分析、集成学习、自然语言处理、图像处理和深度学习。
??本文已收录于专栏:《极客日报》,欢迎免费订阅
此专栏用于分享前沿技术、行业资讯、科技热点、工具测评、优质IT书籍和抽奖包邮送书活动等等
1. 关联规则分析
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
关联规则是形如X→Y的蕴涵式,其中, X和Y分别称为关联规则的先导(antecedent或left-hand-side, LHS)和后继(consequent或right-hand-side, RHS) 。其中,关联规则XY,存在支持度和信任度。

2. 回归分析
回归分析是一种数学模型。当因变量和自变量为线性关系时,它是一种特殊的线性模型。
最简单的情形是一元线性回归,由大体上有线性关系的一个自变量和一个因变量组成;模型是Y=a+bX+ε(X是自变量,Y是因变量,ε是随机误差)。
通常假定随机误差的均值为0,方差为σ2(σ2﹥0,σ^2与X的值无关)。若进一步假定随机误差遵从正态分布,就叫做正态线性模型。一般的,若有k个自变量和1个因变量,则因变量的值分为两部分:一部分由自变量影响,即表示为它的函数,函数形式已知且含有未知参数;另一部分由其他的未考虑因素和随机性影响,即随机误差。
当函数为参数未知的线性函数时,称为线性回归分析模型;当函数为参数未知的非线性函数时,称为非线性回归分析模型。当自变量个数大于1时称为多元回归,当因变量个数大于1时称为多重回归。
3. 分类分析
分类的主要用途和场景是“预测”,基于已有的样本预测新样本的所属类别。例如信用评级、风险等级、欺诈预测等;同时,它也是模式识别的重要组成部分,广泛应用到机器翻译,人脸识别、医学诊断、手写字符识别、指纹识别的图像识别、语音识别、视频识别的领域;另外,分类算法也可以用于知识抽取,通过模型找到潜在的规律,帮助业务得到可执行的规则。
常见应用场景:
对沉默会员做会员重新激活,应该挑选具有何种特征会员商品选取何种促销活动清仓那些广告更适合VIP商家的投放需求提炼特征规则利用的是在构建分类算法时产生的分类规则。
4. 聚类分析
聚类是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
5. 集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)。
集成学习通过将多个学习器进行结合,常可获得比单一学习器更加显著的泛化性能。这对“弱学习器”尤为明显。因此集成学习的理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。但需注意的是,虽然从理论上说使用弱学习器集成足以获得很好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用一些常见学习器的一些经验等,人们往往会使用比较强的学习器。
在一般经验中,如果把好坏不等的东西掺到一起,那么通常结果会是比最坏的要好些,比最好的要坏一些。集成学习把多个学习器结合起来,如何能得到比最好的单一学习器更好的性能呢?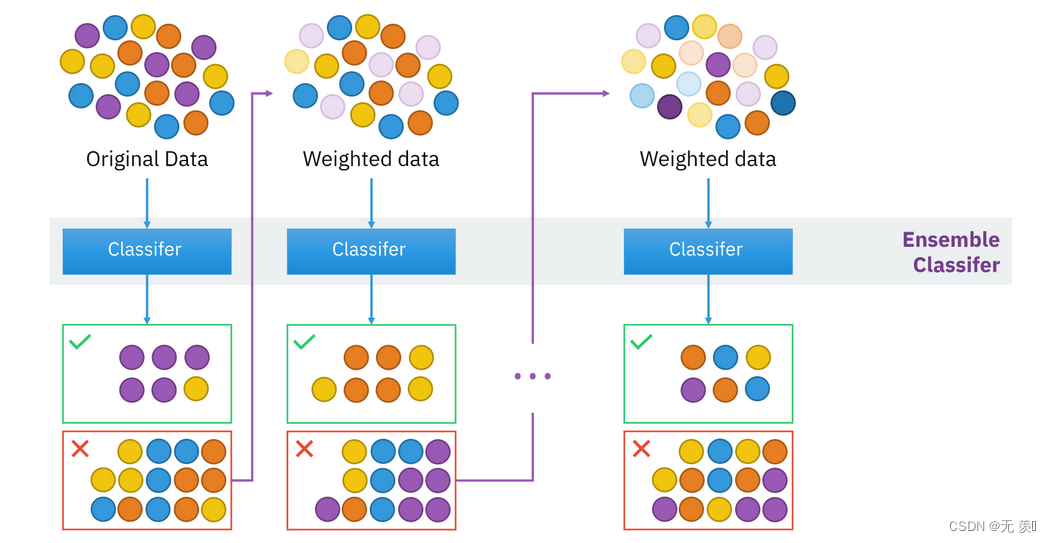
6. 自然语言处理
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面 。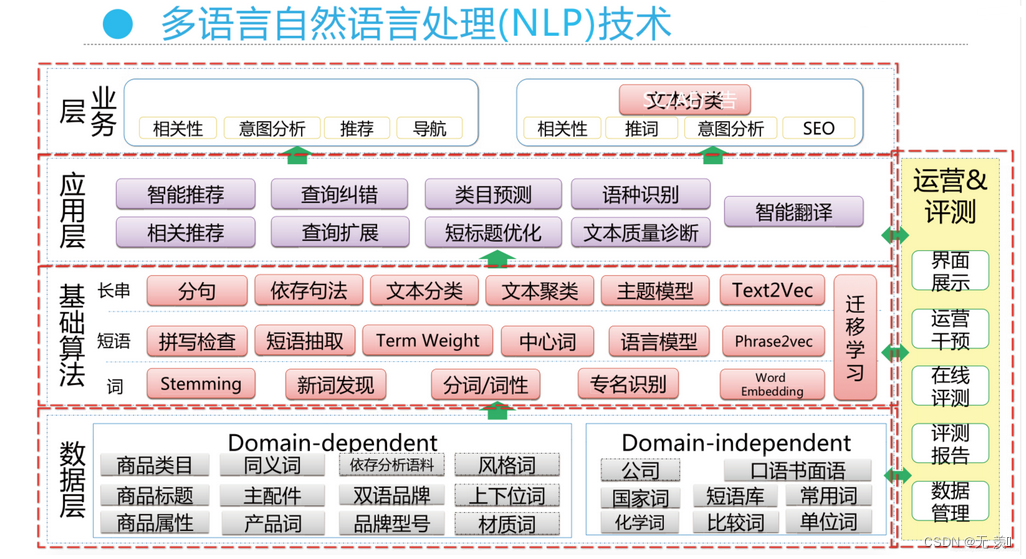
7. 图像处理
图像处理(image processing),用计算机对图像进行分析,以达到所需结果的技术,又称影像处理,图像处理一般指数字图像处理。数字图像是指用工业相机、摄像机、扫描仪等设备经过拍摄得到的一个大的二维数组,该数组的元素称为像素,其值称为灰度值。图像处理技术一般包括图像压缩,增强和复原,匹配、描述和识别3个部分。

8. 深度学习
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
9. 书籍推荐(包邮送书6本)
《数据分析原理与实践》
本书主要采用理论学习与实践操作并重、上层应用与底层原理相结合的方式讲解数据分析师需要掌握的数据分析基础知识,包括基础理论、关联规则分析、回归分析、分类分析、聚类分析、集成学习、自然语言处理、图像处理和深度学习。每章内容从7个方面展开讲解:包括应用场景、算法原理、核心术语、Python编程实践、重点与难点解读、习题和主要参考文献及推荐阅读书目。
本书在编写过程中不仅充分借鉴了国内外著名大学设立的相关课程、专家学者的代表性成果,以及近几年的热门畅销书,而且也考虑到了国内相关课程的教学以及相关从业人员自学的需求。
本书可以满足数据科学与大数据技术、大数据管理与应用、计算机科学与技术、管理工程、工商管理、数据统计、数据分析、信息管理与信息系统、商业分析等多个专业的教师、学生的教学和学习需要,也适合广大从事数据分析工作的人员学习参考。
抽奖送书老规矩(不点赞收藏中奖无效):
1. 点赞收藏文章2. 评论区留言:人生苦短,我用Python!!!(留言才能进入奖池,每人最多留言三条)3. 周日八点爬虫抽奖6人如果不想抽奖当当自营购买链接:http://product.dangdang.com/29440050.html