张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 《随便一记》 - 第461页
C# 垃圾回收机制(GC) 的概述 资源清理 内存管理
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 602次
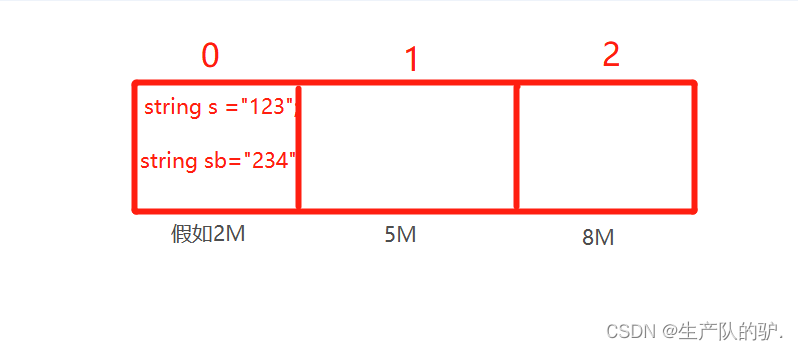
什么是垃圾回收:在编写程序时,会产生很多的数据比如:intstring变量,这些数据都存储在内存里,如果不合理的管理他们,就会内存溢出导致程序崩溃C#内置了自动垃圾回收GC,在编写代码时可以不需要担心内存溢出的问题变量失去引用后GC会帮我们自动回收,但不包括数据流,和一些数据库的连接,这就需要我们手动的释放资源总结:让内存利用率更高什么样子的对象才会给回收?GC只会回收堆的内存,而值类型在栈中的使用完后马上就会给释放,并不需要GC进行处理,堆中的没有被引用或者null的对象才会被回收,静态的变量也不会被回收上面说到他并不会回收一些数据流比如:StreamStreamReaderStreamWriteHttpWebResponse网络
MySQL 高可用之MHA 工作原理和架构,实现MHA高可用实战案例
发布 : shanchahua | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 474次
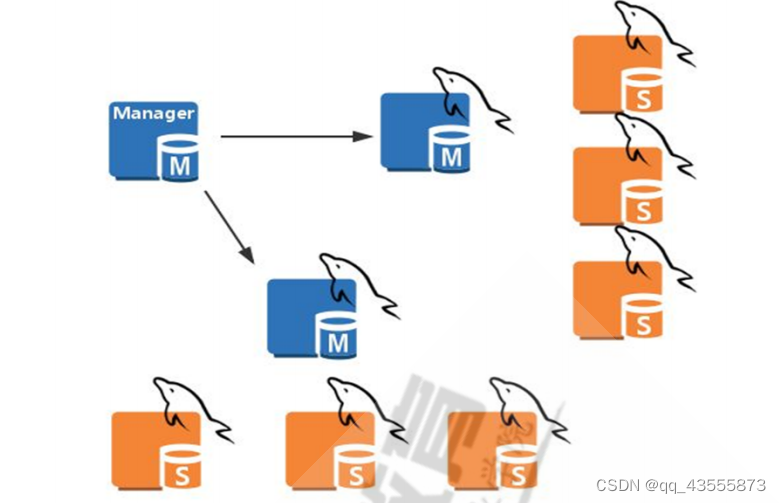
1MHA工作原理和架构MHA集群架构MHA工作原理MHA利用SELECT1AsValue指令判断master服务器的健康性,一旦master宕机,MHA从宕机崩溃的master保存二进制日志事件(binlogevents)识别含有最新更新的slave应用差异的中继日志(relaylog)到其他的slave应用从master保存的二进制日志事件(binlogevents)提升一个slave为新的master使其他的slave连接新的master进行复制MHA软件MHA软件由两部分组成,Manager工具包和Node工具包Manager工具包主要包括以下几个工具:masterha_check_ssh检查MHA的SSH配置状况masterha_check_re
【JavaScript】网页轮播图
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 400次

目录HTML搭建功能实现小圆圈事件左右按钮事件自动播放轮播图也叫焦点图,是网页中比较常见的网页特效。功能:鼠标经过轮播图模块,左右按钮显示,离开隐藏左右按钮。点击右侧按钮一次,图片往左播放一张,以此类推,左侧按钮同理。图片播放的同时,下面小圆圈模块跟随一起变化。点击小圆圈,可以播放相应图片。鼠标不经过轮播图,轮播图也会自动播放图片。鼠标经过,轮播图模块,自动播放停止。HTML搭建分为三部分:1.左右按钮2.图片3.小圆圈index.html<!DOCTYPEhtml><htmllang="en"><head><metacharset="UTF-8"><metahttp-equiv=
MySQL数据库中常用SQL语句
发布 : xiaowang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 444次

开发过程中我们经常会用到各种SQL语句,今天小编就来和大家分享一些简单的SQL语句的使用,便于大家对于项目的开发。1、查询:查询本字段带文字的数据。select*fromstudent where(not age regexp'^[1-9A-Za-z]') andage !='';2、修改:把学生表中年龄为38的数据改为空字符串。UPDATEstudent setage='空白,什么也不写' WHERE age='38';3、模糊查询:模糊查询邮箱列中带有@的数据并去重,DISTINCT代表去重。SELECTDISTINCT studentId,emailfromstudent WHEREemailLIKE'%@%'; 4、
真“火爆”还是假“繁荣” 用数据观察Art Gobblers
发布 : zhumeng | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 516次
万圣节期间,一个名为ArtGobblers的NFT项目正式上线,地板价一度飙升至15ETH,获得6800ETH的交易量,这让本已“遇冷”的NFT市场出现波动,也为人们带来对市场的新期待。ArtGobblers能否像一条“鲶鱼”一样,搅动整个NFT市场,目前还无法确定,但是抛开那些较“虚”的内容,以数读的方式,让我们看ArtGobblers的市场反应和表现。ArtGobblers的运行逻辑是什么?在分析ArtGobblers数据之前,首先需要理解它的运作方式。官网的解释让很投资者云里雾里,NFT(Gobblers)、Token(GOO)、高级NFT(LegendaryGobblers)、联创NFT(DrawnPages),每个都有联动,每个又让人看的懵懂。我们通过简单的
【设计模式】【第七章】【第三方登录场景】【桥接模式】
发布 : jia | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 367次
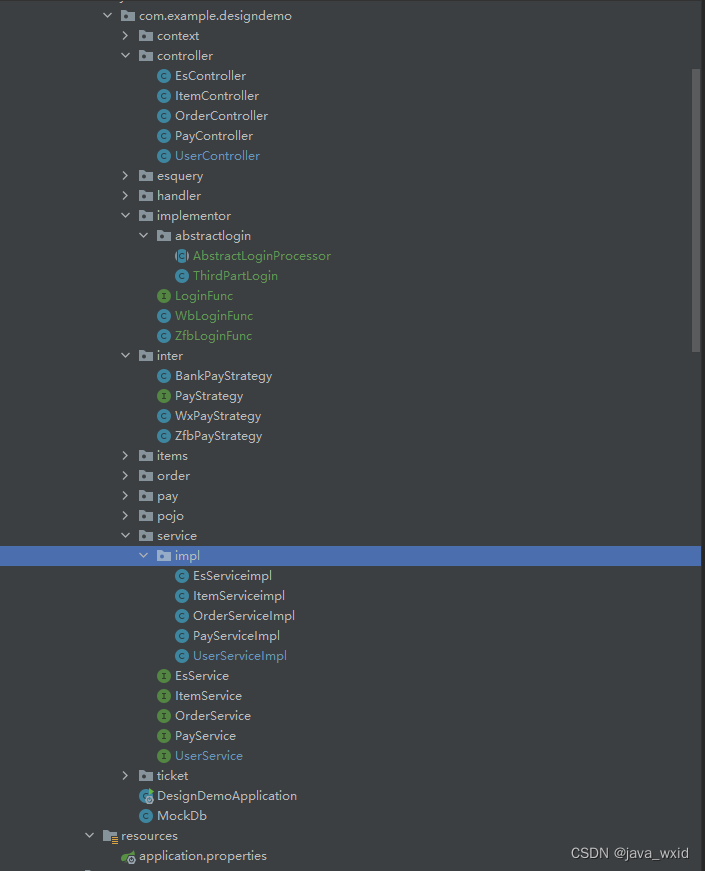
文章目录创建design-demo项目创建UserController创建UserService创建UserServiceImpl创建LoginFunc创建WbLoginFunc创建ZfbLoginFunc创建AbstractLoginProcessor创建ThirdPartLogin创建design-demo项目项目代码:https://gitee.com/java_wxid/java_wxid/tree/master/demo/design-demo项目结构如下(示例):创建UserController代码如下(示例):packagecom.example.designdemo.controller;importcom.example.designdemo.po
生成对抗网络(GANs)
发布 : xiaoniu | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 571次
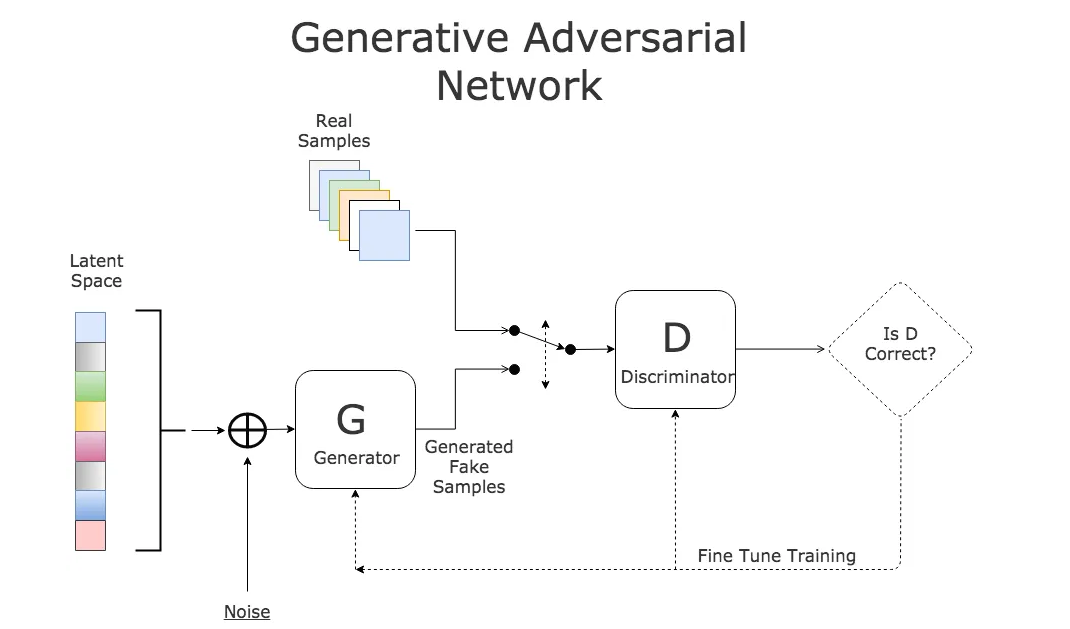
GANs生成对抗网络(GenerativeAdversarialNetworks,GANs)是一种用于捕获训练数据的**分布(distribution)**的神经网络。通过学习到的分布,可以创造新的数据。GAN由两个部分组成:生成器(generator):用G(z)G(z)G(z)表示,输入是(一般为正态分布采样的)随机噪声
深度学习-海康机器人visionmaster图像检索
发布 : xiaowang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 1538次

一:硬件环境:深度学习模块训练运算量较大,依赖GPU进行加速,硬件需独立显卡支撑,目前训练只支持英伟达核心显卡。显卡硬件配置越高,训练及预测耗时越短。1,模型训练:本地训练a)6G及以上显存DL单字符识别训练实现显存自适应,能根据硬件配置自动分配训练显存,从耗时等综合因素考虑推荐采用6G及以上显存显卡训练,如GTX1660Super,RTX2080,RTX3070等b)需去英伟达显卡驱动官网(https://www.nvidia.cn/geforce/drivers/),根据电脑显卡型号下载451.22版本以上驱动c)VisionTrain1.4(VM4.0)版本已支持30系列显卡训练(预测),以前版本不支持支持萤石云服务器训练支持本地云服务器训练2
GFS分布式文件系统
发布 : yang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 515次
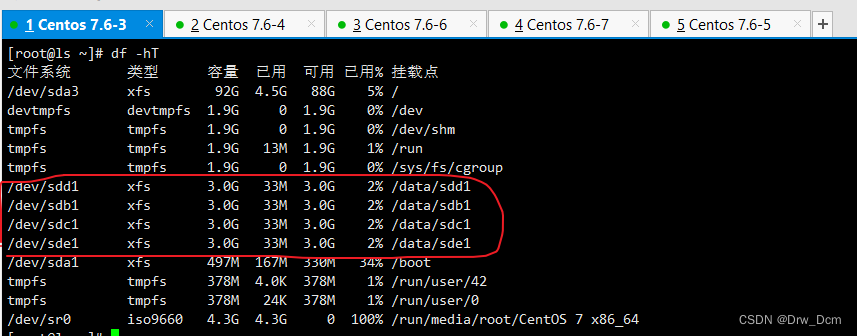
目录一、GlusterFS1.GlusterFS简介2.GlusterFS特点3.GlusterFS术语4.模块化堆栈式架构5.GlusterFS的卷类型(1)分布式卷分布式卷的特点(2)条带卷特点创建条带卷(3)复制卷特点创建复制卷(4)分布式条带卷(5)分布式复制卷二、GlusterFS集群1.准备环境(所有node节点上操作)(1)关闭防火墙(2)磁盘分区,并挂载(3)配置/etc/hosts文件2.安装、启动GlusterFS。(所有node节点上操作) 3.添加节点到存储信任池中(在node1节点上操作) 4.创建卷(1)创建分布式卷(2)创建条带卷(3)创建复制卷(4)创建分布式条带卷(5)创建分布式复制卷
RabbitMQ高可用--镜像队列的原理
发布 : yang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 448次
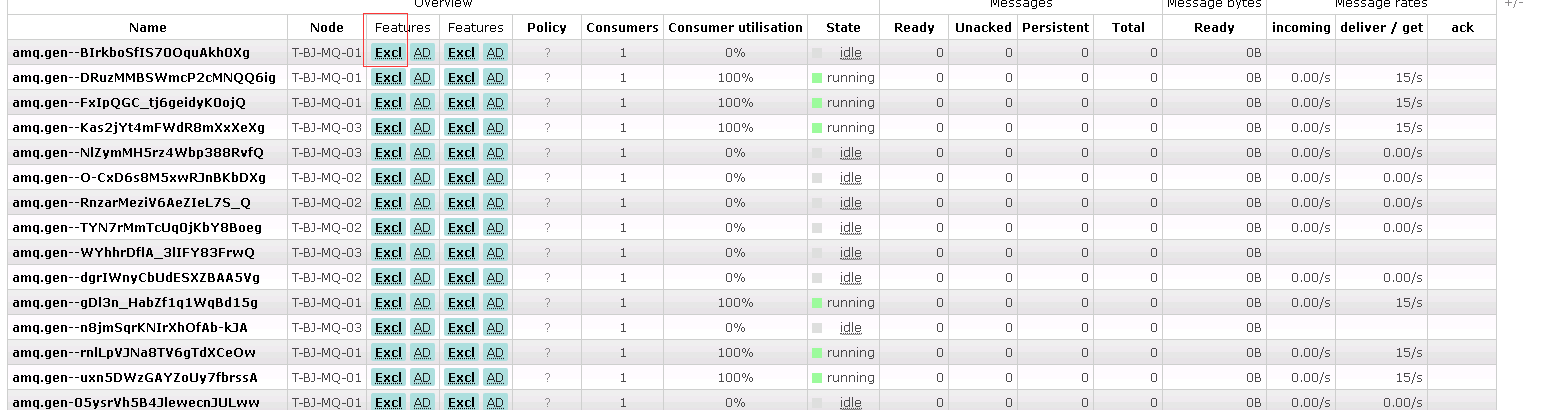
原文网址:RabbitMQ高可用--镜像队列的原理_IT利刃出鞘的博客-CSDN博客简介说明 本文介绍RabbitMQ的镜像队列的原理。镜像队列可以保证RabbitMQ的高可用,防止消息丢失。什么是镜像队列 镜像队列(MirrorQueue):将队列复制到集群的其他Broker节点上,publish到镜像队列的所有消息也被publish到master和所有的slave。如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。队列的复制 镜像队列会将队列复制到集群的其他Broker节点上。消息的复制 生产者publish到镜像队列的所有消息也被publish到master和所有的slave
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1