张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 《随便一记》 - 第519页
6.2 网络钓鱼攻击
发布 : xiaowang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 424次
目录一、了解网络钓鱼二、实验环境三、实验步骤四、实验过程中出现的一些问题一、了解网络钓鱼 网络钓鱼(phishing)由钓鱼(fishing)一词演变而来。在网络钓鱼过程中,攻击者使用诱饵(如电子邮件、手机短信、QQ链接等)将攻击代码发送给大量用户,期待少数安全意识弱的用户“上钩”,进而达到“钓鱼”(如窃取用户的隐私信息)的目的。 网络钓鱼的具体实施过程为:不法分子利用各种手段,仿冒真实网站的URL地址及页面内容,或者利用真实网站服务器程序上的漏洞,在站点的某些网页中插入危险的HTML代码,以此来骗取用户银行卡或信用卡账号、密码等私人资料。 国际反网络钓鱼工作组(Anti-PhishingWorkingGroup,APWG)
美团后端笔试2022.08.13
发布 : 郑州电脑哥 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 493次
文章目录1.魔法外卖2.打扫房间3.扑克牌游戏4.三元组变形问题附加题:树的分支最大值昨天刚刚笔试结束,然后今天抽空给大家整理一下,然后简单说一下思路。整场笔试下来,整体难度一般,只不过在第三题扑克牌游戏的时候进行的不是很顺利,附加题难度一般,不知道有没有小伙伴和我一样时间耗费在第三题上面的。1.魔法外卖题目描述:炸鸡店拥有一名会传送魔法的外卖派送员。该外卖派送员派送单子时,可以消耗时间t来正常派送单子(一次只能派送一个单子,不能多个同时派送),也可以使用魔法不耗费时间地隔空瞬间投送。现在炸鸡店在时刻0接收到了若干炸鸡订单,每个单子都有它的截止送达时间。外卖派送员需要保证送达时间小于等于这个截止时间。现在询问外卖员最少要使用几次魔法来保证没有外卖超时。输入描
MySQL主从复制详细介绍
发布 : xiaowang | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 925次

一、主从复制的目的MySQL内建的复制功能是构建基于MySQL的大规模、高性能应用的基础,复制功能的目的是构建高性能的应用,同时也是高可用性、可扩展性、灾难恢复、备份以及数据仓库等工作的基础。比较常见的用途有以下几种:数据分布:备份特定数据库负载均衡:读写分离高可用性和故障切换:从库的存在可以缩短宕机时间MySQL升级测试:使用一个更高版本的MySQL作为备库,保证在升级全部实例前,查询能够在备库按照预期进行二、主从复制的原理和步骤简单的说就是master将数据库的改变写入binarylog二进制日志,这个日志会记录下所有修改了数据库的SQL语句(insert,update,delete,grant等),slave同步这些二进制日志,并根据这些二进制日志进行数据操作,
晚饭都没吃,我一前端帮后端做了一点SQL优化,才避免了通宵
发布 : 郑州电脑哥 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 515次

1、前言其实感觉自己做的这点sql优化也算是比较常规的,没什么太大的难度。最近上线了一个新系统,刚试点运行,用户量不大还没什么大问题。但随之培训和大规模用户开始使用后,问题出现了。而且出现了好多问题,大部分都是后端的,这里就不细讲了。说说与我前端相关的吧。由于我会一点后端。后端准备叫我开mysql客户端,删除多余的数据删就删吧,但是要删除的多余数据还有点多删除以后发现,还他妈有好多要删除的数据,原来三个后端也同时在删除数据于是我优化了三次sql语句,轻松实现批量删除如果下次再有这种类似的情况,我得写个相关的小工具了真的太浪费时间了,也不明白后端为啥不想想办法呢?可能是因为线上bug的压力,没空想吧2、看看重复记录根据这三个筛选条件,本来是可以确定唯一记录的。可
爬虫过程和反爬
发布 : jie | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 524次
文章目录爬虫过程一、获取网络数据(requests、selenium)1.`requests`2.`selenium`3.常见反爬4.找数据接口二、解析数据(从获取到的网络数据中提取有效数据)1.正则表达式2.基于`css`选择器的解析器(`bs4`)3.基于`xpath`的解析器(`lxml`)三、保存数据:`csv`、Excel四、完整策略爬虫过程爬虫:获取网络数据(公开的网络)网络数据来源:网站对应的网页、手机APP一、获取网络数据(requests、selenium)1.requests定义Python获取网络数据的第三方库(基于http或https协议的网络请求)应用场景1)直接请求网页地址2)对提供网页数据的数据接口发送请求基本用法1)
推荐一个 Web 端自动化神器 - Automa
发布 : hao1 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 515次
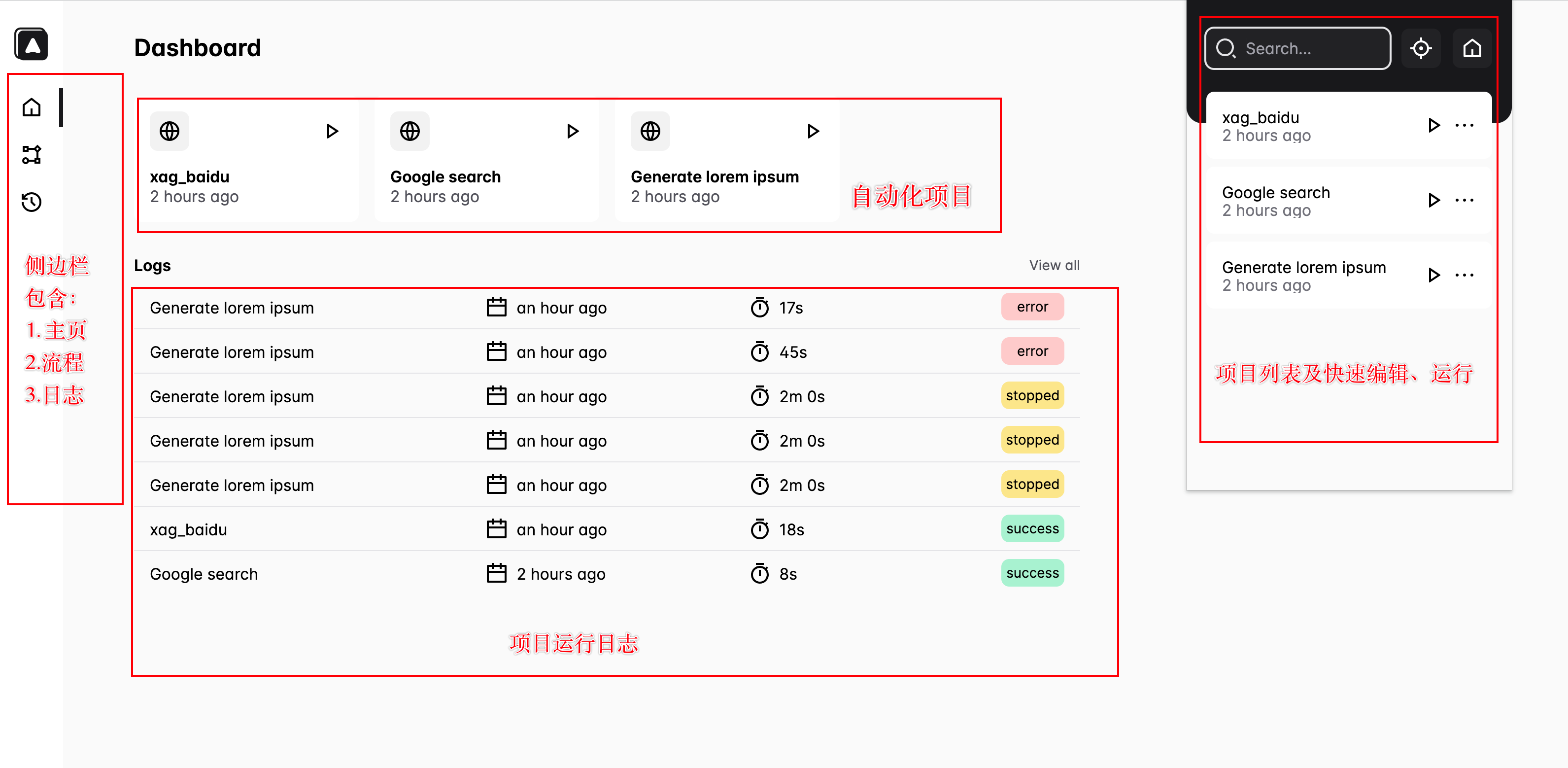
目录前言1.Automa 介绍2.功能介绍3.实战一下4.最后前言大家好,我是不二!之前推荐过很多优秀的Web自动化工具,比如:Selenium、Helium、Cypress、Pyppeteer等利用它们实现自动化的前提是必须安装依赖、下载浏览器驱动,并且还需要掌握一定的编码基础那有没有一款针对零基础编码,低代码的工具,能够帮助我们完成Web端的自动化呢?本篇文章将介绍另外一款自动化工具,即:Automa1.Automa 介绍Automa是一款Chrome插件,它能针对Chrome浏览器完成一系列自动化操作,并且可以执行重复性任务、网页截图、数据爬虫等功能项目地址:GitHub-AutomaApp/automa:Abro
MyBatis流式查询
发布 : jia | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 888次
MyBatis流式查询1.应用场景说明MyBatispreview:JDBC三种读取方式:1.一次全部(默认):一次获取全部。2.流式:多次获取,一次一行。3.游标:多次获取,一次多行。在开发中我们经常需要会遇到统计数据,将数据导出到excel表格中。由于生成报表逻辑要从数据库读取大量数据并在内存中加工处理后再生成Excel返回给客户端。如果数据量过大,采用默认的读取方式(一次性获取全部)会导致内存飙升,甚至是内存溢出。而导出数据又需要查询大量的数据,因此采用流式查询就比较合适了。2.模拟excel导出场景1.创建海量数据的sql脚本CREATETABLEdept(/*部门表*/deptnoMEDIUMINTUNSIGNEDNOTNULLDEFA
MySQL学习第二部分:事务的理解
发布 : ofheart | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 873次
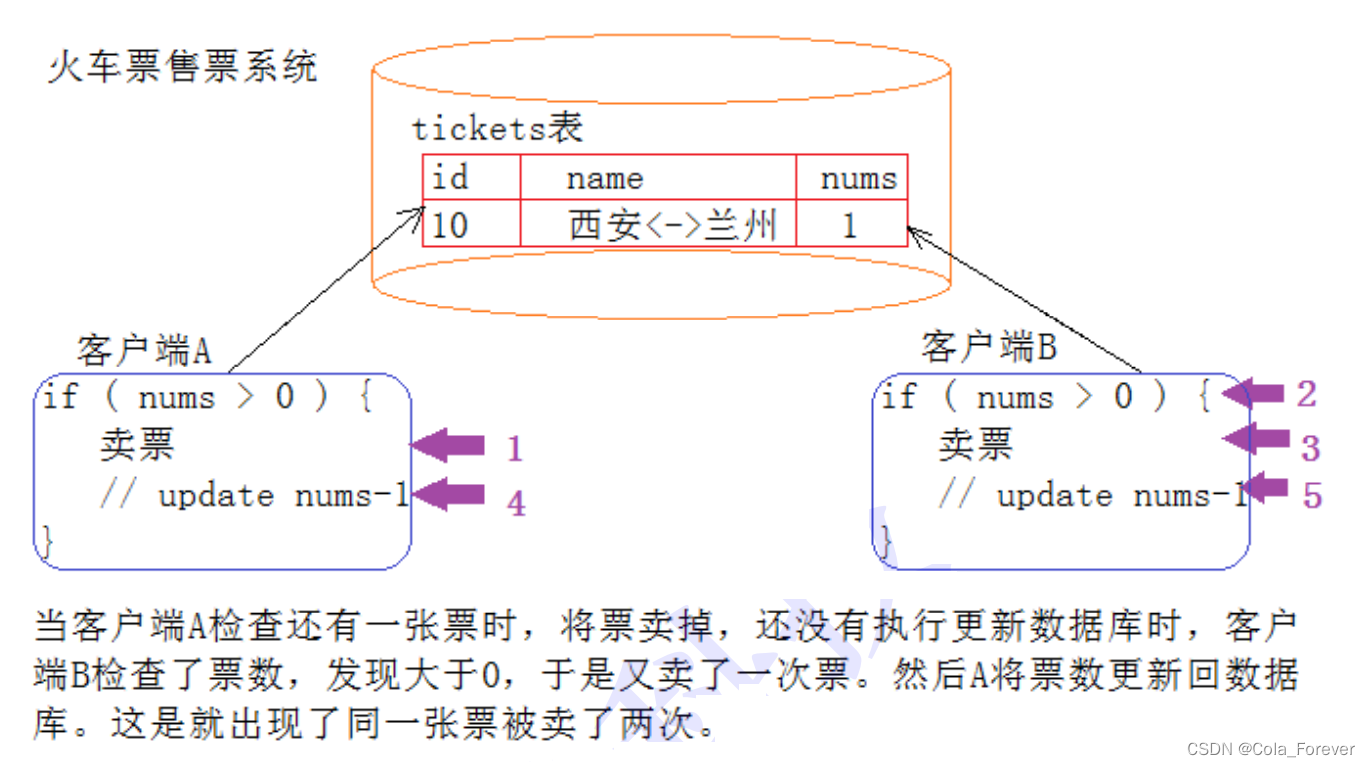
当MySQL的CURD不加控制,会有什么问题?以买车票为例CURD满足什么属性,能解决上述问题?1.买票的过程得是原子的吧2.买票互相应该不能影响吧3.买完票应该要永久有效吧4.买前,和买后都要是确定的状态吧因此引出了事务的概念!什么是事务?说白了我们为完成某个功能使用的每条sql语句都是事务,有的事务是一条sql语句组成,有的事务是多条sql语句组成,比如我想让A的钱转给B那我们就要执行两条sql语句,一条把A的余额减少,一条把B的余额增加,这两条加起来才是一个完整的事务为避免上述类似火车票问题,一个完整的事务,绝对不是简单的sql集合,还需要满足如下四个属性:为什么会出现事务MySQL中只有使用了Innodb数据库引擎的数据库或表才支持事务!MyISA
【精灵雪花特效】(HTML+JS+CSS+代码+效果)
发布 : admin08 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 429次

效果展示其余的效果,大家自己去体验叭!代码下雪.html<!doctypehtml><html><head><metacharset="utf-8"><title>雪花——追光者♂</title><scripttype="text/javascript"src="js/jquery.min.js"></script><style>html,body{width:100%;height:100%;margin:0;padding:0;overflow:hidden;}.container{width:100%
MySQL - 全局锁、表级锁、行级锁、元数据锁、自增锁、意向锁、共享锁、独占锁、记录锁、间隙锁、临键锁、死锁
发布 : hao1 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 541次
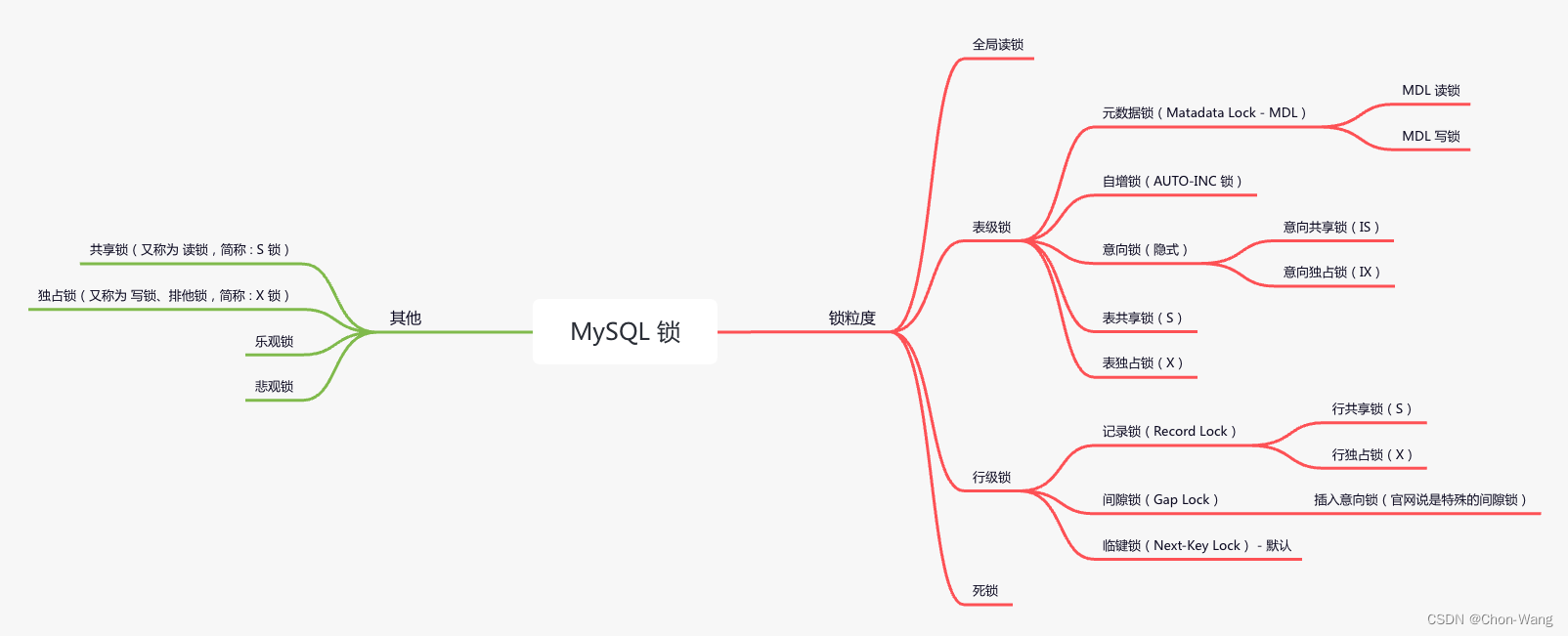
#前言本篇只介绍MySQL锁的基本知识。我的MySQL版本是MySQL5.7.34,建议使用MySQL5.6及之后的版本。##先上一个图##为什么要使用锁?个人理解:使用锁就是实现事务的原子性与隔离性、数据的一致性。##扩展阅读DDL:数据定义语言(DataDefinitionLanguage),使用create、alter、drop来定义数据库的库、表、列等,操作的是数据表结构。DML:数据操纵语言(DataManipulationLanguage),使用select、insert、update、delete操作数据库中的数据。DQL:数据控制语言(DataQueryLan
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1